Design philosophy
Core principles behind Redistill:
- Optional persistence – no disk I/O on the hot path by default; snapshots only when you opt in.
- Multi-threaded – utilize all CPU cores rather than a single event loop thread.
- Lock-free reads – concurrent GETs without global locks via a sharded DashMap.
- Zero-copy – use reference-counted buffers for values to avoid copying on reads.
- Production-ready – authentication, TLS, monitoring and health checks built in.
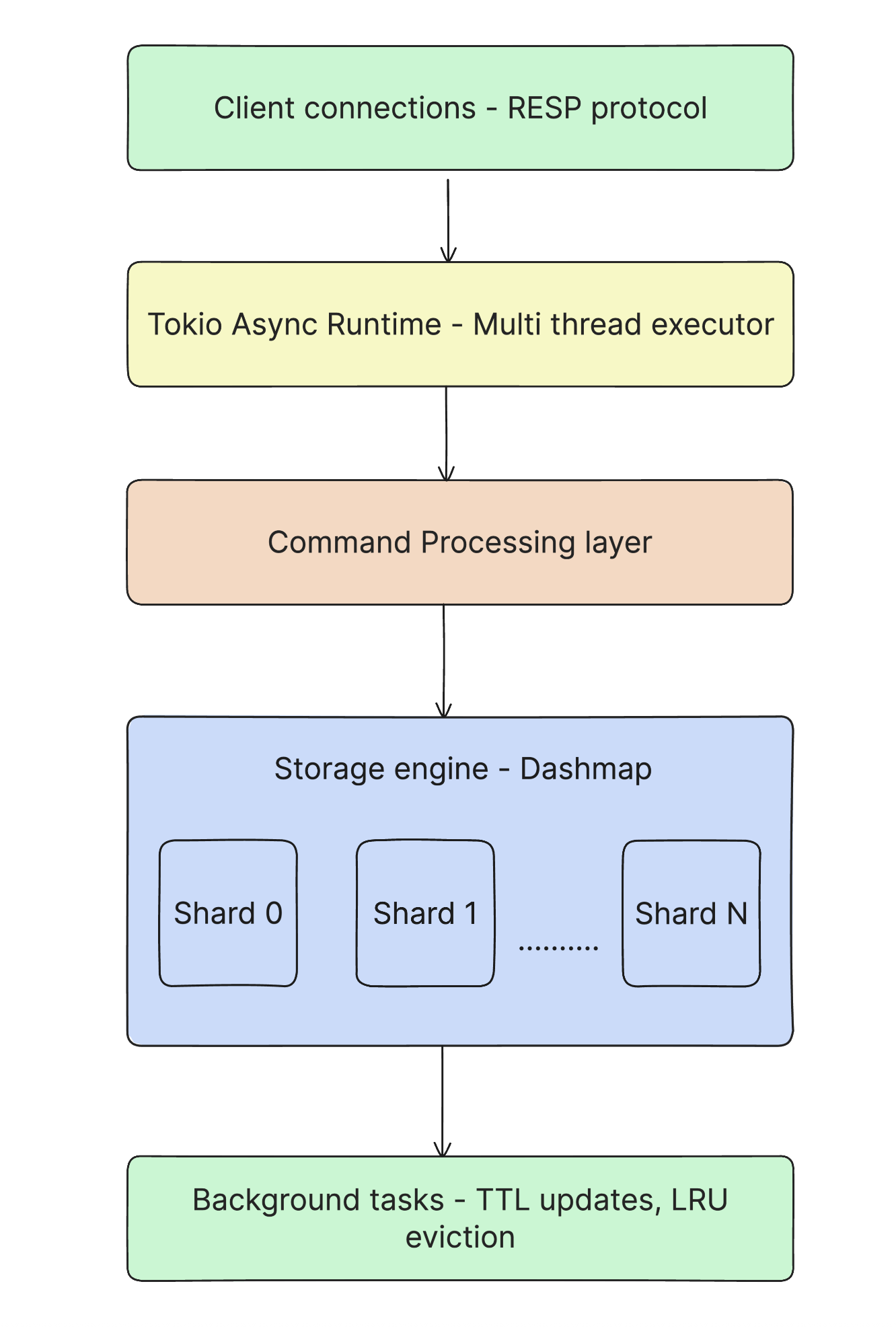
High-level architecture
Redistill is implemented in Rust, using the Tokio async runtime and DashMap for the in-memory store. The key components are:
- A multi-threaded Tokio runtime for accepting connections and handling commands.
- A sharded, concurrent hash map (DashMap) used as the primary key-value store.
- A RESP protocol parser and command dispatcher compatible with Redis clients.
- Optional snapshot persistence layer that runs in the background when enabled.
The upstream documentation includes an architecture diagram. To reuse it here, copy
Redistill_Architecture.png from the main project's docs/img/ into this site's
assets/img/ directory.
Performance optimizations
1. Optional persistence
Redis combines AOF and RDB by default, incurring write amplification and fsync overhead. Redistill disables persistence by default, eliminating disk I/O from the hot path. When you enable snapshots, they run in the background and do not block GET/SET handling.
2. Multi-threaded command processing
Instead of a single-threaded event loop, Redistill uses Tokio's multi-threaded scheduler and work-stealing to distribute connections and commands across cores. This improves throughput under high concurrency.
3. Sharded store & lock-free reads
The in-memory store is a DashMap with many shards (2048 recommended, 4096 for GET-heavy workloads). Reads acquire shard-local locks with minimal contention and can proceed concurrently across shards.
4. Zero-copy buffers
Values are stored using Bytes, a reference-counted buffer type. Cloning a value for a read does
not copy the underlying bytes, improving memory efficiency and cache locality.
5. Batched writes & probabilistic LRU
Redistill batches operations internally and uses probabilistic LRU updates to reduce atomic overhead:
- Atomic counters are updated in batches instead of per-operation.
- LRU timestamps are updated probabilistically (e.g., 10% of the time), which is sufficient for eviction decisions.
Trade-offs
What you gain
- 4.5× higher single-instance throughput compared to Redis.
- 5× lower p50 latency in benchmarks.
- Excellent scaling with read-heavy and pipelined workloads.
- Lower infrastructure costs thanks to fewer required instances.
What you trade off
- No real-time durability (no AOF/write-ahead logging).
- No built-in replication or clustering (client-side sharding recommended today).
- No advanced data structures like lists, sets, sorted sets, streams, or modules.
- Not suitable as a primary system of record or for financial/transactional data.
Use cases
Where Redistill excels
- Read-heavy workloads (70–90%+ GETs).
- Pipelined traffic with depths of 16–128.
- Session storage, API response caching, feature flags, rate limiting, and leaderboards.
- Ephemeral or regenerable data where small amounts of loss on restart are acceptable.
Not recommended for
- Primary, durable data storage.
- Workloads requiring replication or multi-DC failover out of the box.
- Highly stateful, write-heavy transactional systems.
When to use Redistill vs Redis
| Requirement | Redistill | Redis |
|---|---|---|
| Maximum single-instance throughput | Best choice (≈9.07M ops/s) | Slower (≈2.03M ops/s) |
| Clustered, horizontally scaled throughput | Manual or proxy-based sharding | Redis Cluster built in |
| Strict durability & replication | Snapshot-only (optional) | AOF, RDB, replication |
| Rich data structures | Strings, counters, hashes | Lists, sets, sorted sets, streams, etc. |
| High-performance cache with optional warm restarts | Excellent fit | Good fit but lower per-instance performance |